Background and Motivation
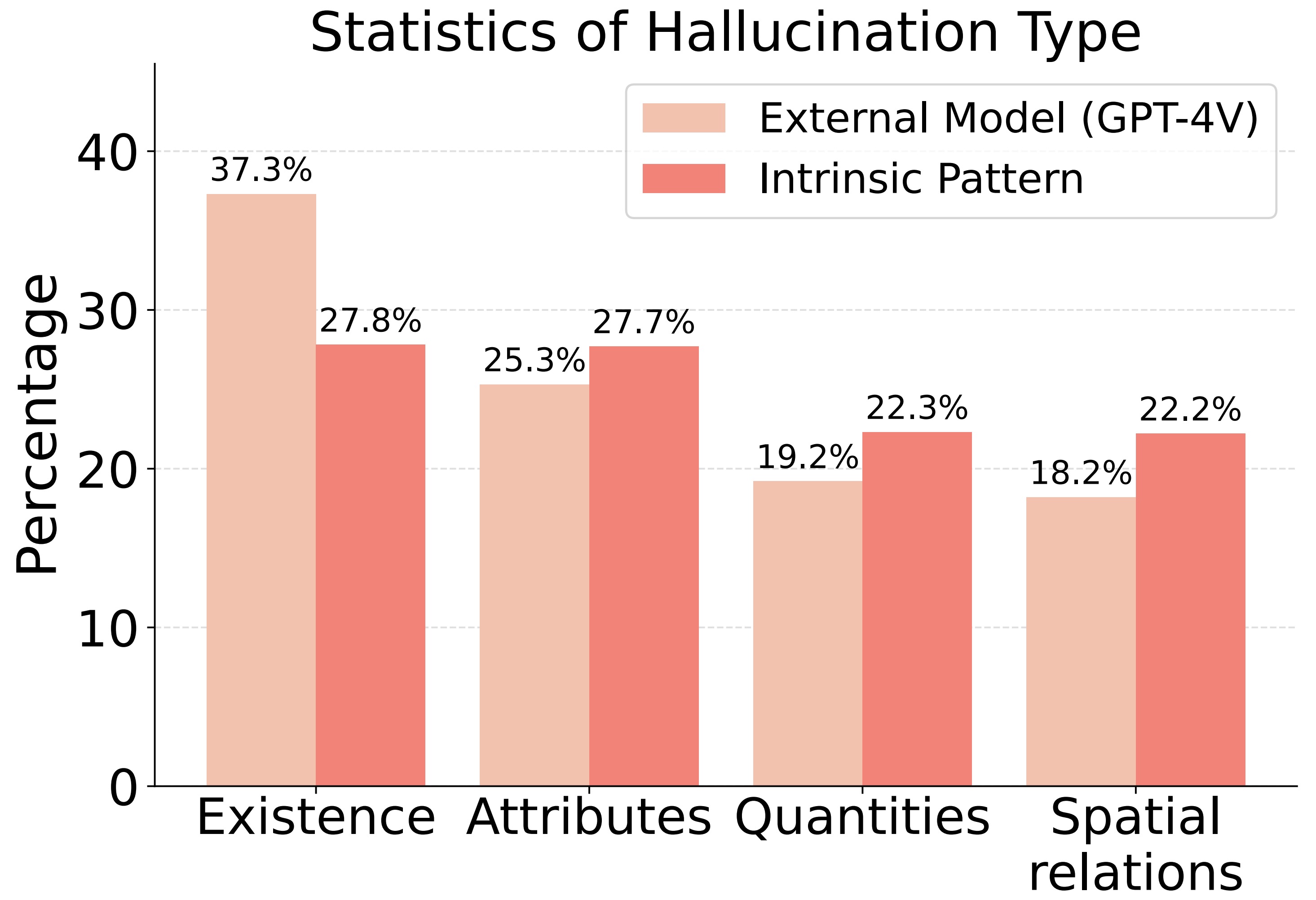
Despite their success, Vision Language Models (VLMs) suffer from a critical limitation: visual hallucinations. They might confidently describe non-existent objects, misrepresent attributes, or misjudge spatial relationships, posing significant risks in safety-critical scenarios.
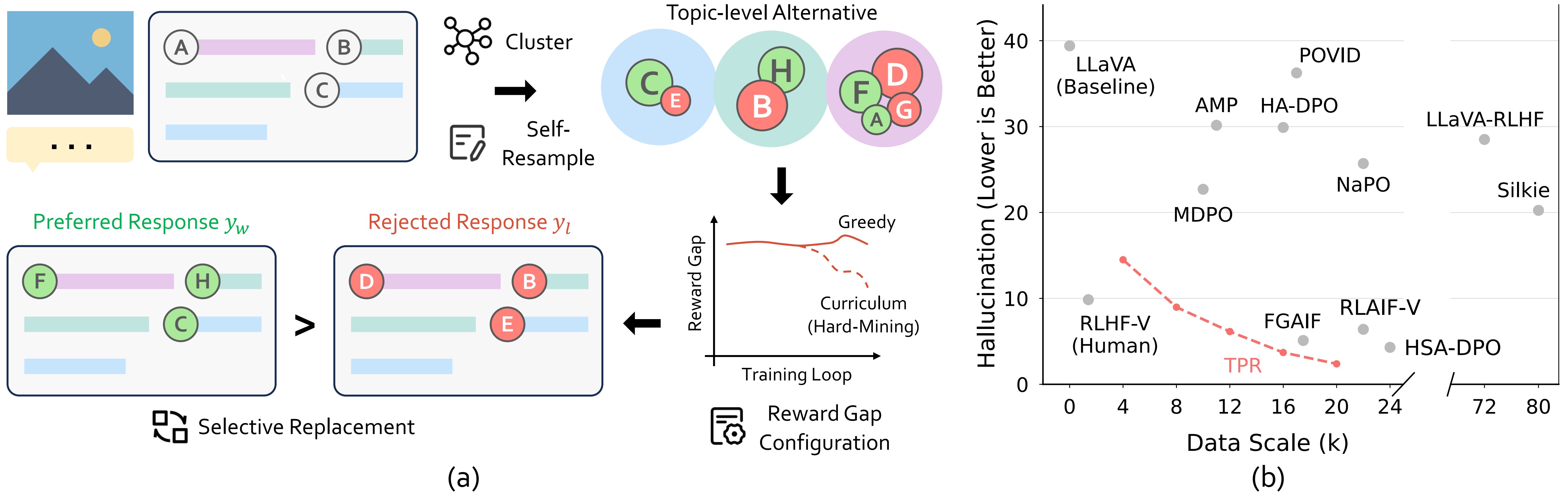
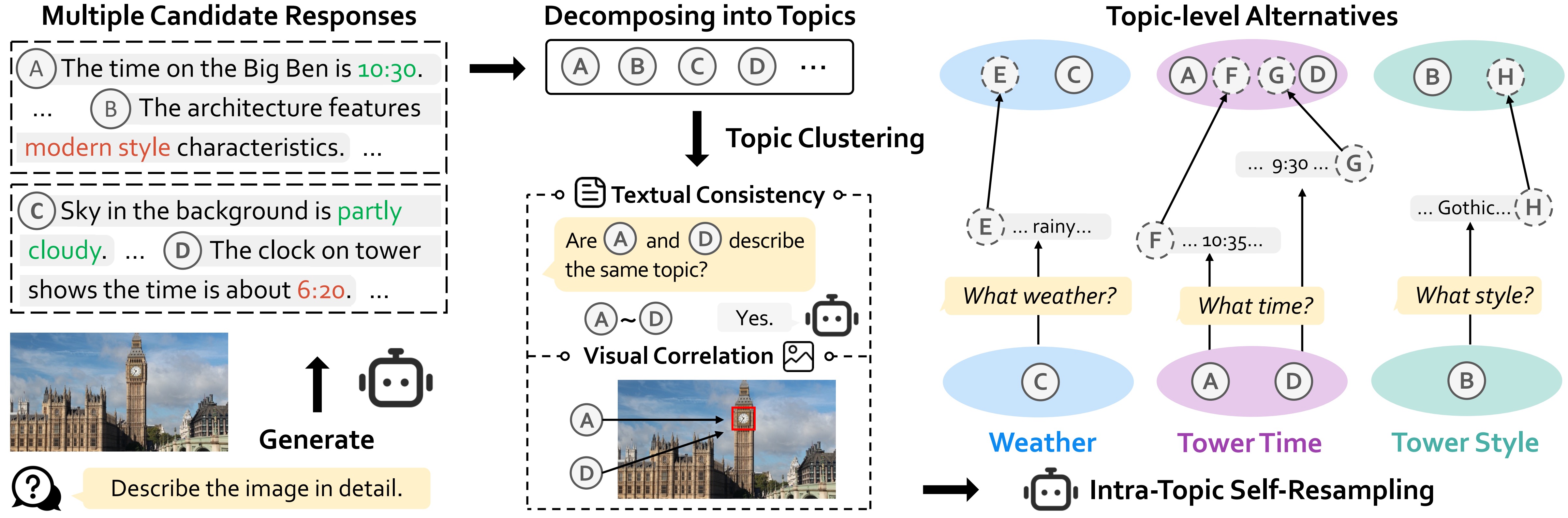
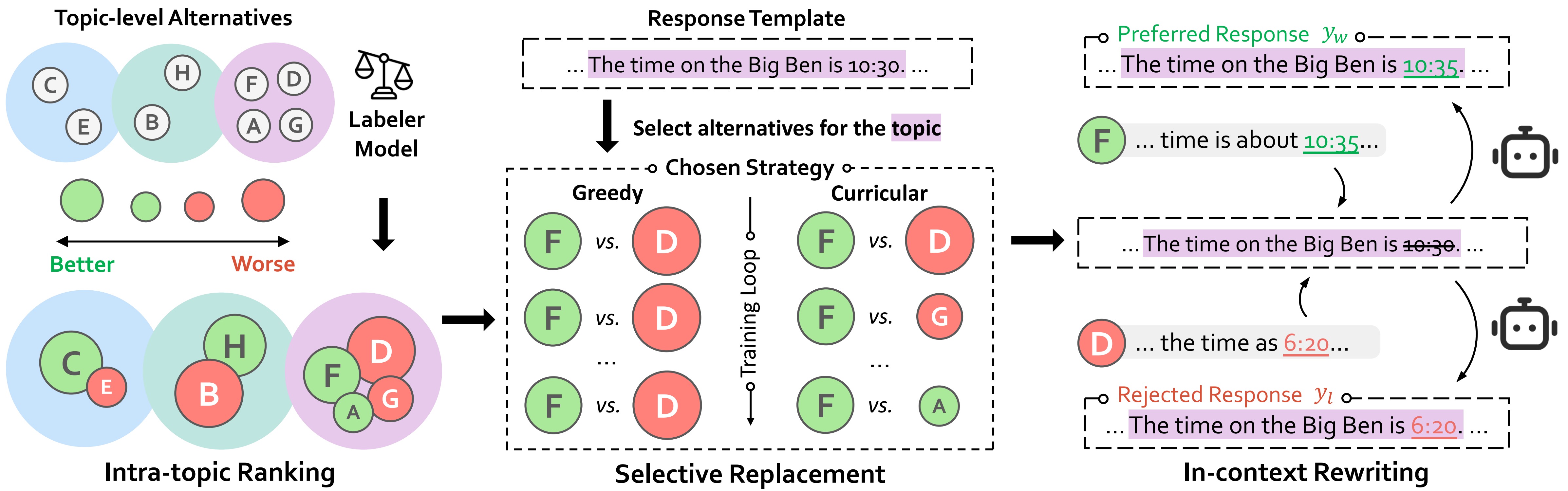
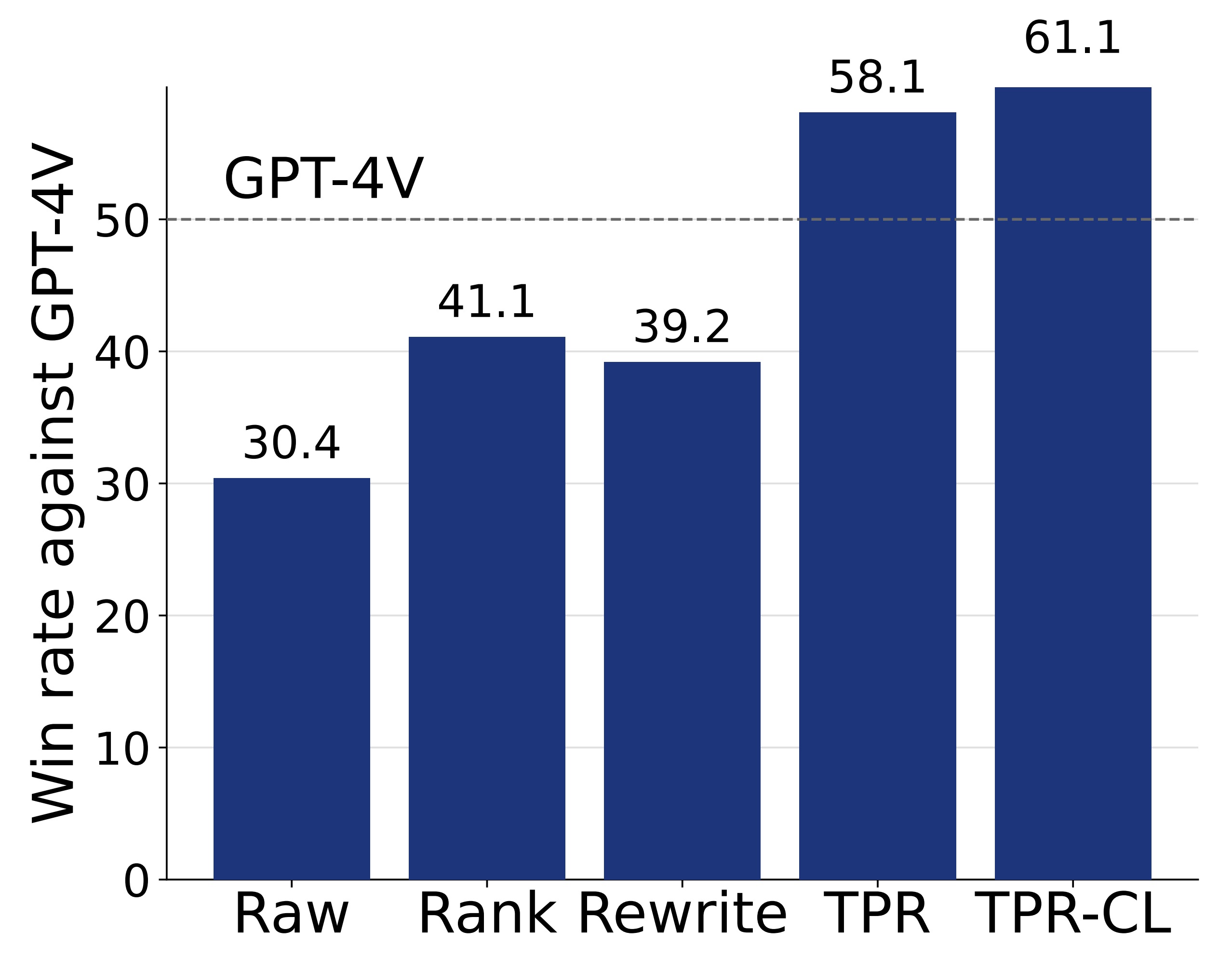
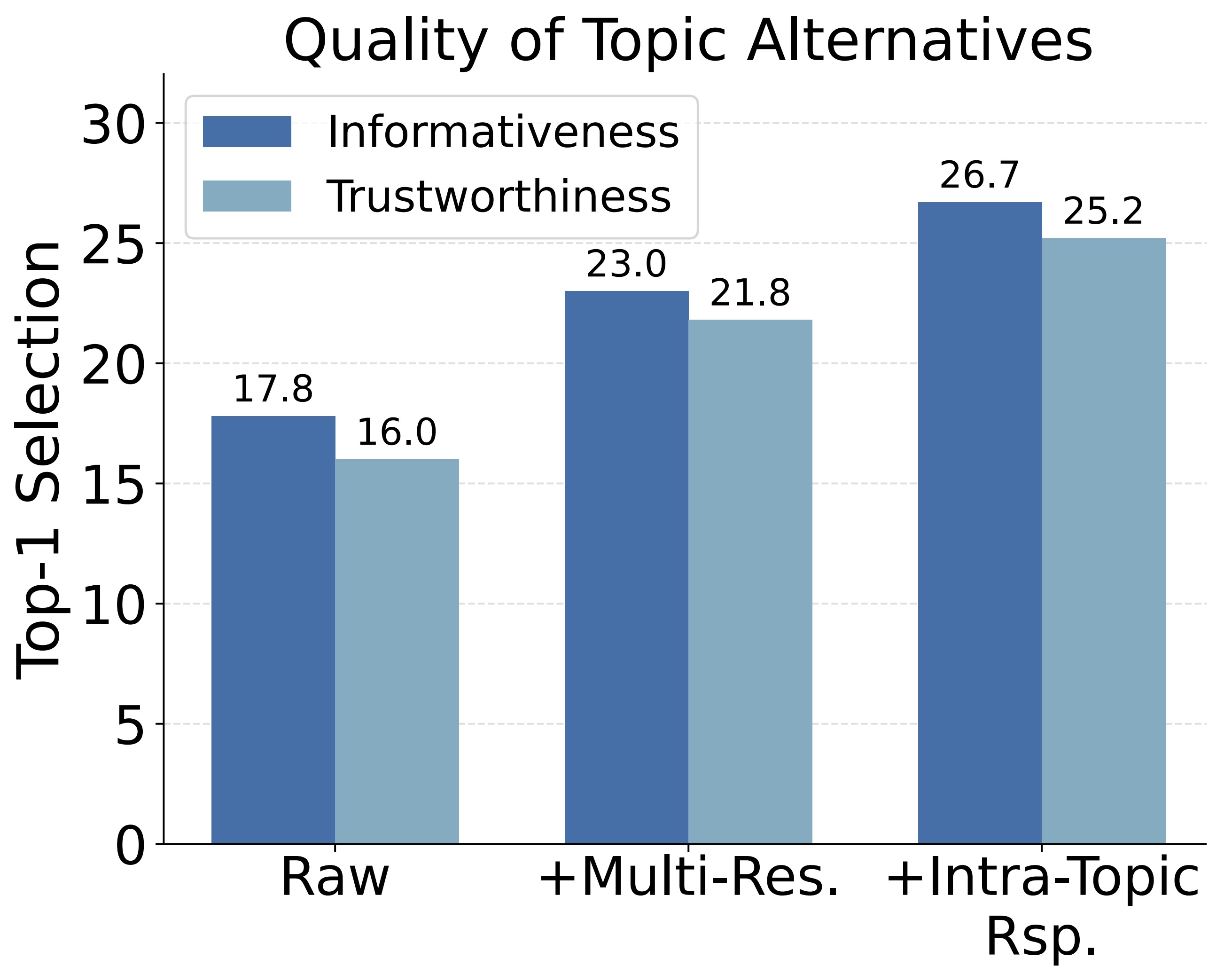
Recent efforts to mitigate hallucinations increasingly leverage alignment techniques like Direct Preference Optimization (DPO). However, the success of DPO critically hinges on the true reward gaps within preference pairs. Current methods, relying on ranking or rewriting strategies, struggle to optimize these reward gaps systematically. A core difficulty lies in precisely characterizing and strategically manipulating the reward gap configuration to guide the model effectively.